Google Gemini 3.5 Flash vs. Pro: The Next Phase of Low-Latency Reasoning
Following the Google I/O updates, Gemini 3.5 Flash dominates low-latency workloads. We dissect the tech behind its optimization and what to expect from the upcoming Gemini 3.5 Pro reasoning model.
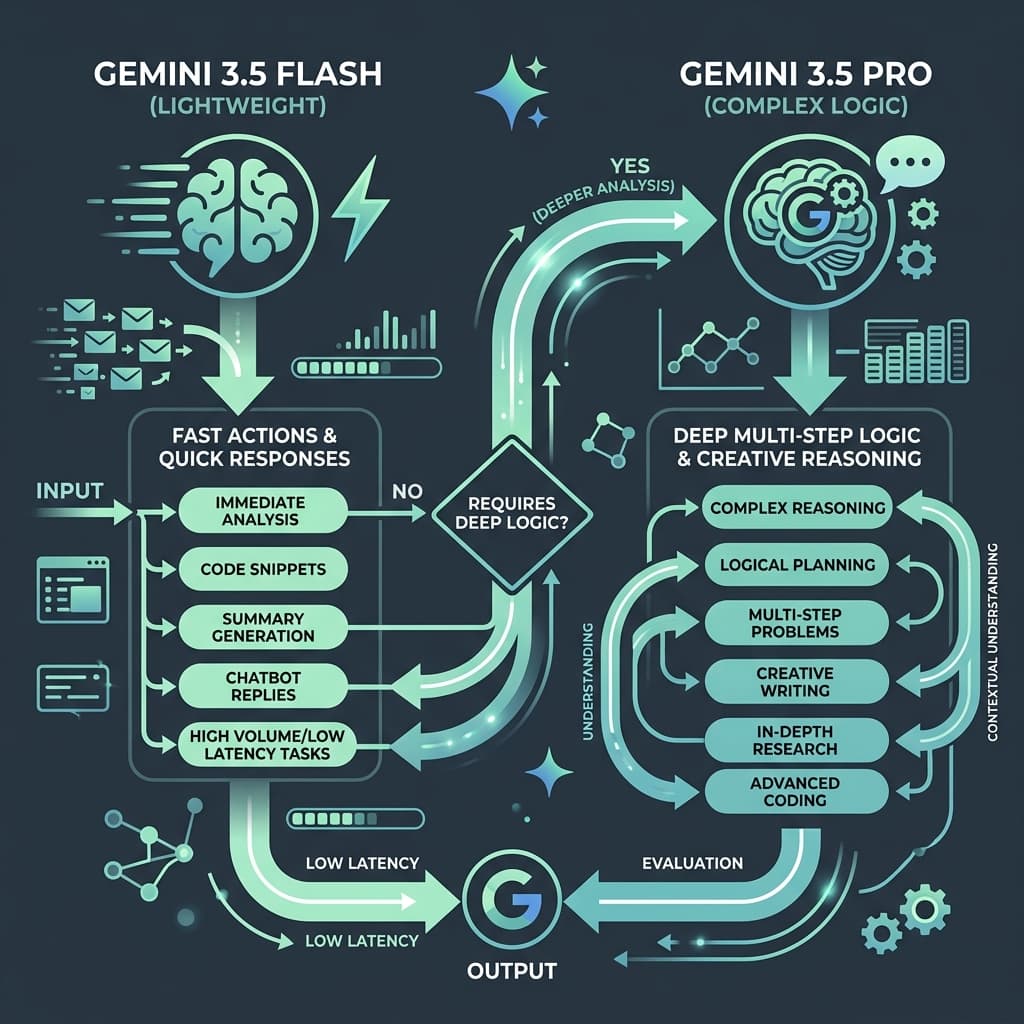
Google Gemini 3.5: Balancing Speed and Cognitive Depth
In the highly competitive artificial intelligence arena, Google's release of the Gemini 3.5 series signals a strategic focus on two fronts: hyper-fast local execution and advanced server-side reasoning. With Gemini 3.5 Flash serving as the primary driver for low-latency operations, and anticipation building around the reasoning capabilities of Gemini 3.5 Pro, developers have access to a versatile model suite for diverse applications.
Gemini 3.5 Flash: Optimized for Latency and Speed
Gemini 3.5 Flash is designed to handle high-frequency, low-latency tasks. By reducing model parameter weights and optimizing cache architectures, Google has achieved a throughput increase of over 40% compared to previous generations. This makes Gemini 3.5 Flash ideal for interactive tools, including:
- Real-time Code Conversion: Performing quick conversions like converting JSON files to YAML on the fly without causing interface lag.
- Telemetry Scanning: Deconstructing request parameters, such as parsing browser user agents or identifying screen dimension specifications.
- Syntax Formatting: Beautifying raw programming inputs like SQL strings and JSON objects instantly.
Gemini 3.5 Pro: Tackling Complex Reasoning
While Flash excels at speed, Gemini 3.5 Pro is architected to address complex reasoning gaps. It features an expanded context window and dedicated multi-step validation logic, enabling the model to execute graduate-level scientific queries, resolve database schema conflicts, and design complex software systems.
Architectural Flow Comparison
| Feature Category | Gemini 3.5 Flash | Gemini 3.5 Pro (Expected) |
|---|---|---|
| Average Latency | Under 200ms | 800ms - 2s |
| Context Capacity | 1 Million Tokens | 2+ Million Tokens |
| Ideal Use Cases | Real-time UI updates, API formatting, quick text filters | Multi-file refactoring, system architecture audits, proof solving |
| Deployment Mode | High-efficiency API or local Wasm context | Large-scale cloud compute nodes |
Summary
Google's dual approach with Gemini 3.5 highlights that AI development is no longer just about raising raw parameter counts. By optimizing Gemini 3.5 Flash for immediate edge execution and Gemini 3.5 Pro for deep mathematical and logical reasoning, Google provides a balanced toolkit for modern software engineering.
Try it free